










Industrial-grade Data Fabric Archetypes: Selection and Vendors
- Application-Centric Industrial Data Fabric
- Asset-Centric Industrial Data Fabric
- Edge-Centric Industrial Data Fabric
- Industrial DataOps-Centric Fabric
- Data Science-Centric Industrial Data Fabric
- IT/Enterprise-Centric Industrial Data Fabric
- What’s Next? The Reality of Hybrid Fabrics and Charting Your Course
Contents
- Application-Centric Industrial Data Fabric
- Asset-Centric Industrial Data Fabric
- Edge-Centric Industrial Data Fabric
- Industrial DataOps-Centric Fabric
- Data Science-Centric Industrial Data Fabric
- IT/Enterprise-Centric Industrial Data Fabric
- What’s Next? The Reality of Hybrid Fabrics and Charting Your Course
Originally Published May 2025, on ARCweb.com by Colin Masson
This is Blog Post 4 in our series on the Industrial Data Fabric. In our previous posts, we discussed the importance of data quality (Blog Post 1), identified the essential building blocks (Blog Post 2), and described the key emerging archetypes (Blog Post 3). In this post, we connect the building blocks to the archetypes, exploring how to assemble each patte
by examining the prioritized components, the types of vendors likely to provide them, and key recommendations for successful implementation, all aimed at supporting diverse user roles, Industrial DataOps pipelines, and enabling Industrial-grade AIOps solutions built by data and AI/ML teams.
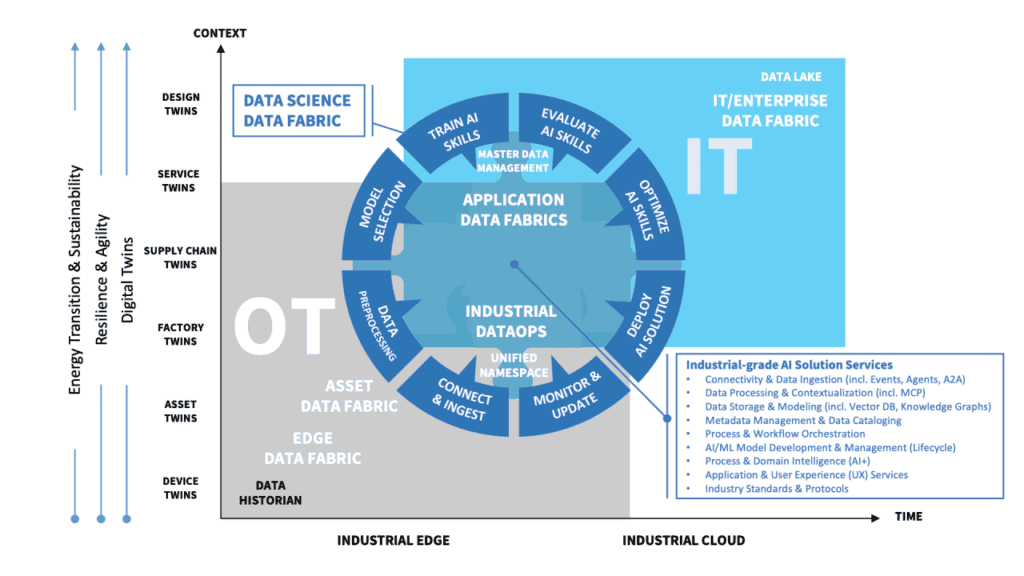
As we discussed in Blog Post 3, different Industrial Data Fabric (IDF) archetypes are emerging as organizations assemble their data foundations. These archetypes – Application-Centric, Asset-Centric, Edge-Centric, Industrial DataOps-Centric, Data Science-Centric, and IT/Enterprise-Centric – represent distinct strategic patte
s for tailoring the data fabric to meet the needs of IT, OT, and the teams building Industrial AI/AIOps solutions. Understanding these patte
s helps organizations prioritize the specific data fabric building blocks (like Connectivity, Gove
ance, or AI Support) they need to focus on, and identifies the types of vendors best suited to provide those components.
Drawing from ARC Advisory Group’s research, let’s examine the prioritized building blocks, likely vendor types, and key assembly recommendations for each archetype. While we describe the types of vendors relevant to each archetype here, specific vendor evaluations, detailed market positioning, and comprehensive vendor lists are covered in depth in ARC Advisory Group’s Industrial-grade Data Fabric Market Landscape and Technology Archetypes Reports.
Application-Centric Industrial Data Fabric
This archetype focuses on assembling building blocks needed to support the data requirements of specific OT or Enterprise business applications. Refer to Blog Post 2 on Assembling Your Industrial-Grade Data Fabric: Identifying the Building Blocks for more details and context on the numbered building blocks below.
Prioritized Building Blocks & Rationale:
3. Data Connectivity and Integration: Strong emphasis on seamless connectivity to the specific OT and/or Enterprise systems (historians, control systems, asset management, CRM, ERP, PLM, Supply Chain platforms) relevant to the target application or business process. This is the foundational building block for getting the necessary data from wherever the application needs it.
4. Data Quality and Gove
ance: Focus on ensuring the quality and context of data streams consumed by the specific application. Data quality is a critical building block for reliable application performance and the insights they generate. Gove
ance is tailored to the application’s data needs and compliance requirements.
7. Support for Industrial AI and Analytics: Prioritizing integrations with analytics or AI/ML tools tailored for the specific application (e.g., predictive maintenance algorithms, supply chain optimization models, customer chu
prediction). This building block delivers the application’s core intelligence or analytical capabilities.
2. Solution Capabilities and Architecture: Focus on data fabric components that can structure and deliver data in formats suitable for the application, potentially including support for specialized data structures like vector databases or knowledge graphs if required by the application’s architecture or use case.
Likely Vendor Types:
Organizations adopting this archetype will prioritize vendors specializing in data connectivity and integration for the relevant application domains (both OT and Enterprise). They will also look for vendors offering analytics or AI/ML platforms tailored for specific application types, and potentially database or data structuring technologies (like vector database or knowledge graph providers) required by the application’s data architecture. Collaboration between OT, IT, and application-specific data experts is key to assembling these components effectively.
Key Recommendations for Assembling this Archetype:
- Start with a clearly defined, high-value business process or application use case with strong justification, which dictates which data fabric building blocks are essential.
- Prioritize connecting to the data sources (OT and Enterprise) most critical for that application, leveraging comprehensive connectivity building blocks.
- Focus on data quality measures and context relevant to the specific application’s needs, often requiring domain knowledge (OT or Enterprise business process expertise) and specific quality building blocks.
- Select data fabric components that can deliver data in the format and structure required by the application, including support for specialized data types if necessary.
Asset-Centric Industrial Data Fabric
This archetype assembles components to create comprehensive digital representations or digital twins of industrial assets. Refer to Blog Post 2 on Assembling Your Industrial-Grade Data Fabric: Identifying the Building Blocks for more details and context on the numbered building blocks below.
Prioritized Building Blocks & Rationale:
3. Data Connectivity and Integration: Deep connectivity to asset management systems, historians, and IoT platforms generating asset data is a primary requirement for gathering all asset-related building blocks of data.
4. Data Quality and Gove
ance: Ensuring the accuracy and completeness of asset-specific data streams, often gove
ed by OT standards. Reliable data is a crucial building block for accurate asset twins and AIOps.
2. Solution Capabilities and Architecture: Focus on platforms supporting asset modeling and digital twin creation as core functional building blocks.
Likely Vendor Types:
Organizations focusing on asset performance management will prioritize vendors with strong capabilities in integrating data from asset management systems, historians, and IoT platforms. Vendors offering digital twin and asset modeling platforms are also key in this archetype. Collaboration between OT asset experts and data modelers is crucial for effectively assembling the data and modeling components.
Key Recommendations for Assembling this Archetype:
- Focus on unifying diverse data streams related to critical assets, leveraging comprehensive connectivity building blocks.
- Prioritize platforms with strong digital twin and asset modeling capabilities, selecting the right functional building blocks.
- Ensure OT teams are involved in defining data requirements and context, linking domain expertise to the data quality and modeling building blocks.
Edge-Centric Industrial Data Fabric
This archetype prioritizes building blocks for processing and analyzing data closer to its source at the industrial edge for real-time needs. Refer to Blog Post 2 on Assembling Your Industrial-Grade Data Fabric: Identifying the Building Blocks for more details and context on the numbered building blocks below.
Prioritized Building Blocks & Rationale:
3. Data Connectivity and Integration: Robust connectivity to edge devices and sensors, supporting industrial protocols, is the essential building block for data acquisition at the source.
6. Deployment and Integration: Strong support for edge deployments and integration with edge hardware/platforms is a fundamental building block for localized processing.
2. Solution Capabilities and Architecture: Focus on edge computing capabilities, low-latency processing, and edge analytics as key functional building blocks for real-time action and edge AIOps.
Likely Vendor Types:
Organizations requiring real-time decision-making at the edge will prioritize vendors offering industrial edge computing platforms and industrial IoT gateways with robust data integration capabilities suitable for challenging operational environments. Close collaboration between OT architects and edge platform specialists is needed to assemble and deploy these edge building blocks.
Key Recommendations for Assembling this Archetype:
- Identify use cases requiring immediate, localized decision-making, guiding the selection of edge building blocks.
- Prioritize vendors with proven edge deployment capabilities and performance.
- Ensure seamless integration between edge processing and central data systems, involving both IT and OT, leveraging connectivity and deployment building blocks.
Industrial DataOps-Centric Fabric
This archetype focuses on assembling components that streamline and automate data pipelines for the efficient flow and contextualization of operational data. Refer to Blog Post 2 on Assembling Your Industrial-Grade Data Fabric: Identifying the Building Blocks for more details and context on the numbered building blocks below.
Prioritized Building Blocks & Rationale:
3. Data Connectivity and Integration: Broad OT connectivity, but also strong capabilities for data transformation, contextualization, and standardization (supporting UNS). These are crucial building blocks for creating well-formed data pipelines.
4. Data Quality and Gove
ance: Emphasis on automated data quality checks, lineage tracking for operational data, and gove
ance suitable for real-time streams. These quality and gove
ance building blocks are foundational to DataOps trust and reliability.
6. Deployment and Integration: Support for edge and hybrid deployments, integration with OT systems, and potentially UNS brokers. These deployment building blocks enable flexible DataOps pipeline architectures.
2. Solution Capabilities and Architecture: Focus on real-time data processing, stream analytics, and specific DataOps features as core functional building blocks.
Likely Vendor Types:
This archetype requires collaboration between OT architects, data engineers, and potentially data scientists. Key vendor types include specialists in Industrial DataOps platforms, edge platforms with strong data processing capabilities, and providers of technologies supporting emerging standards like Unified Namespaces (UNS) via MQTT brokers or similar.
Key Recommendations for Assembling this Archetype:
- Prioritize establishing robust DataOps practices for OT data pipelines.
- Evaluate platforms based on their ability to contextualize and standardize diverse OT data streams in real-time, selecting appropriate transformation and integration building blocks.
- Consider adopting Unified Namespace principles for improved interoperability, leveraging supportive connectivity building blocks.
- Foster collaboration between OT data experts and data engineering teams, which is critical for DataOps success.
Data Science-Centric Industrial Data Fabric
This archetype emphasizes assembling components to provide data scientists with seamless access to diverse IT and OT data for building and deploying AI models. Refer to Blog Post 2 on Assembling Your Industrial-Grade Data Fabric: Identifying the Building Blocks for more details and context on the numbered building blocks below.
Prioritized Building Blocks & Rationale:
3. Data Connectivity and Integration: Broad connectivity to both IT (ERP, CRM, Data Lakes) and OT systems (Historians, MES, Sensors). This wide range of connectivity is a fundamental building block for unified data access.
4. Data Quality and Gove
ance: Robust metadata management, data cataloging, and lineage tracking across IT/OT data are crucial for discovery and trust – essential gove
ance building blocks for data scientists.
7. Support for Industrial AI and Analytics: Strong integration with data science tools (Jupyter, MLflow), AI/ML platforms, and features for model development and deployment. These AI/Analytics building blocks directly serve the target user.
6. Deployment and Integration: Flexibility in cloud/hybrid deployments and seamless integration with data science environments. These deployment building blocks ensure the data is accessible where the data scientists work.
Likely Vendor Types:
Requires strong collaboration between IT, OT, and the data and AI/ML teams. Organizations will likely prioritize vendors offering comprehensive enterprise data fabric or lakehouse platforms with strong data cataloging, self-service access features, and robust AI/ML capabilities. Cloud hyperscalers also play a significant role in providing many of these building blocks and related services.
Key Recommendations for Assembling this Archetype:
- Invest in a comprehensive data catalog covering both IT and OT assets, leveraging metadata management building blocks.
- Provide data scientists with gove
ed, self-service access to diverse, high-quality data, utilizing gove
ance and access building blocks. - Ensure the chosen platform can scale to handle large, complex datasets for AI/ML model training and deployment, selecting scalable capability building blocks.
- Establish clear collaboration protocols between IT, OT, and the data and AI/ML teams, which is key to integrating diverse data sources and skills and building AIOps.
IT/Enterprise-Centric Industrial Data Fabric
This archetype prioritizes assembling components for enterprise-wide data consolidation, gove
ance, and reporting, primarily driven by IT needs. Refer to Blog Post 2 on Assembling Your Industrial-Grade Data Fabric: Identifying the Building Blocks for more details and context on the numbered building blocks below.
Prioritized Building Blocks & Rationale:
4. Data Quality and Gove
ance: Strong emphasis on enterprise-wide data gove
ance, compliance features, security policies, and audit trails. These are the paramount building blocks for enterprise IT.
5. Security and Compliance: Robust security features, access controls, encryption, and adherence to enterprise compliance standards are paramount. Security is a core building block for enterprise data.
3. Data Connectivity and Integration: Focus on integrating transactional data from core IT systems (ERP, CRM, Finance) into a centralized lakehouse, with OT data often being a secondary (though necessary) feed. IT connectivity is the primary focus here.
2. Solution Capabilities and Architecture: Preference for established enterprise data warehousing/lakehouse platforms with strong gove
ance features as core architectural building blocks.
Likely Vendor Types:
Driven mainly by IT, with input from finance and compliance teams. Collaboration with OT and data/analytics teams is needed for data integration and reporting/analytics insights. Vendor types strong in enterprise data warehousing, lakehouses, and comprehensive data gove
ance platforms are preferred.
Key Recommendations for Assembling this Archetype:
- Prioritize establishing a strong, centralized data gove
ance framework, focusing on gove
ance building blocks. - Focus on integrating core enterprise transactional systems first, leveraging IT connectivity building blocks.
- Ensure robust security and compliance features meet enterprise standards, selecting appropriate security building blocks.
- Define clear processes for integrating necessary OT data into the enterprise lakehouse, requiring IT/OT collaboration and utilizing connectivity building blocks for OT.
What’s Next? The Reality of Hybrid Fabrics and Charting Your Course
Understanding these archetypes provides a valuable framework for prioritizing the right data fabric building blocks based on your primary drivers and user needs. However, the reality for most industrial organizations involves combining elements from several archetypes to create a robust, hybrid fabric that addresses the full complexity of their data landscape.
Reminder: While we have described the types of vendors relevant to example archetypes in this blog post, specific vendor evaluations, detailed market positioning, and comprehensive vendor lists are covered in depth in ARC Advisory Group’s Industrial-grade Data Fabric Market Landscape and Technology Archetypes Reports, and ARC Advisory Group clients can seek specific guidance for their industrial organization through their client managers.
The Industrial-grade Data Fabric Series:
- Blog Post 1: The Foundation of Industrial AI: Addressing the Data Quality Imperative
- Blog Post 2: Assembling Your Industrial-grade Data Fabric: Identifying the Building Blocks
- Blog Post 3: Industrial-grade Data Fabric Archetypes: Understanding the Core Patte
s - Blog Post 4: Industrial-grade Data Fabric Archetypes: Selection and Vendors (this blog)
In our concluding post (Blog Post 5) in this series, we will discuss this reality of assembling hybrid Industrial Data Fabrics to empower diverse roles fully, and offer some guidance on charting your course toward a successful Industrial AI future.
Engage with ARC Advisory Group
For ARC Advisory Group recommendations for navigating the AI Wars, closing the digital divide by embracing Industrial AI, assembling your Industrial-grade Data Fabric, and gove
ing and guiding major decisions about enterprise, cloud, industrial edge, and AI software, please contact Colin Masson at cmasson@arcweb.com or set up a meeting with me, or my fellow Analysts at ARC Advisory Group.
About the Author

Colin Masson
Director of Research, ARC Advisory Group
Reference:
Masson, C (2025). Industrial-grade Data Fabric Archetypes: Selection and Vendors. Available at: Industrial-grade Data Fabric Archetypes: Selection and Vendors | LinkedIn [Accessed: 10th May 2025].




